Selenium 的安装和基本使用
Selenium 的安装
Selenium 是一个自动化测试工具,利用它我们可以驱动浏览器执行特定的动作,如点击、下拉等操作。对于一些 JavaScript 渲染的页面来说,这种抓取方式非常有效。下面我们来看看 Selenium 的安装过程。
相关链接:
- 官方网站:http://www.seleniumhq.org
- GitHub:https://github.com/SeleniumHQ/selenium/tree/master/py
- PyPI:https://pypi.python.org/pypi/selenium
- 官方文档:http://selenium-python.readthedocs.io
- 中文文档:http://selenium-python-zh.readthedocs.io
使用 pip 安装即可:
pip install selenium
Selenium 支持非常多的浏览器,如 Chrome、Firefox、Edge 等,还有 Android、BlackBerry 等手机端的浏览器。
可以用如下方式进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.Safari()
browser = webdriver.Android()
browser = webdriver.Ie()
browser = webdriver.Opera()
browser = webdriver.PhantomJS()
使用任一种游览器都需要先安装相应的驱动,下面介绍Chrome、Firefox和无头游览器PhantomJS的安装方法:
ChromeDriver 的安装
安装Chrome 浏览器对应版本的 ChromeDriver,才能驱动 Chrome 浏览器完成相应的操作。
相关链接:
- 官方网站:https://sites.google.com/a/chromium.org/chromedriver
- 下载地址:https://chromedriver.storage.googleapis.com/index.html
我们需要根据Chrome 浏览器的版本去下载,点击 Chrome 菜单 “帮助”→“关于 Google Chrome”,即可查看 Chrome 的版本号。
我的Chrome游览器的版本为88.0.4324.182
国内下载谷歌地址可能比较慢,我们可以通过阿里的镜像站下载,地址:http://npm.taobao.org/mirrors/chromedriver/
这里我下载最接近的版本88.0.4324.96:https://cdn.npm.taobao.org/dist/chromedriver/88.0.4324.96/chromedriver_win32.zip
然后将解压出来的chromedriver.exe文件放入一个已经加入环境变量的目录中,或者将chromedriver.exe所在目录加入环境变量。
这里推荐将chromedriver.exe放入python安装目录下的Scripts目录中。
验证安装:
C:\Users\Think>chromedriver
Starting ChromeDriver 88.0.4324.96 (68dba2d8a0b149a1d3afac56fa74648032bcf46b-refs/branch-heads/4324@{#1784}) on port 9515
Only local connections are allowed.
Please see https://chromedriver.chromium.org/security-considerations for suggestions on keeping ChromeDriver safe.
ChromeDriver was started successfully.
弹出以上提示表示安装成功。
在程序中测试,执行如下 Python 代码:
from selenium import webdriver
browser = webdriver.Chrome()
运行之后,如果弹出一个空白的 Chrome 浏览器,则证明所有的配置都没有问题。否则可能是 ChromeDriver 版本和 Chrome 版本不兼容,本地可能安装了多个Chrome 游览器,需要检查。
GeckoDriver 的安装
对于 Firefox 来说,也可以使用同样的方式完成 Selenium 的对接,这时需要安装另一个驱动 GeckoDriver。
相关链接:
- GitHub:https://github.com/mozilla/geckodriver
- 下载地址:https://github.com/mozilla/geckodriver/releases
同样需要事先安装Firefox 浏览器。
同样也可以在阿里云镜像网站下载,地址:http://npm.taobao.org/mirrors/geckodriver/
当前最新版本为 0.29,下载地址:
http://npm.taobao.org/mirrors/geckodriver/v0.29.0/geckodriver-v0.29.0-win64.zip
下载后同样将解压的geckodriver.exe放入一个已经加入环境变量的目录中。
验证安装:
C:\Users\Think>geckodriver
1614247352940 geckodriver INFO Listening on 127.0.0.1:4444
有类似以上提示表示安装成功。
在程序中测试,执行如下 Python 代码:
from selenium import webdriver
browser = webdriver.Firefox()
运行后,若弹出一个空白的 Firefox 浏览器,则证明所有的配置都没有问题;否则检查之前的每一步配置。
PhantomJS 的安装
PhantomJS 是一个无界面的、可脚本编程的 WebKit 浏览器引擎,Selenium 支持 PhantomJS,运行时不会弹出一个浏览器了。
相关链接:
- 官方网站:http://phantomjs.org
- 官方文档:http://phantomjs.org/quick-start.html
- 下载地址:http://phantomjs.org/download.html
- API 接口说明:http://phantomjs.org/api/command-line.html
下载 PhantomJS:
阿里的npm服务同样提供了相应的镜像目录:
http://npm.taobao.org/mirrors/phantomjs
这里我下载非beta的最新版:http://npm.taobao.org/mirrors/phantomjs/phantomjs-2.1.1-windows.zip
解压后,将对应的bin目录加入环境变量中。
可以在命令行下输入phantomjs,测试一下:
C:\Users\Think>phantomjs
phantomjs> ^C终止批处理操作吗(Y/N)? y
C:\Users\Think>phantomjs -v
2.1.1
C:\Users\Think>
如果可以进入到 PhantomJS 的命令行,那就证明配置完成了。
python代码测试一下:
from selenium import webdriver
from IPython.display import Image
browser = webdriver.PhantomJS()
browser.get('https://www.baidu.com')
print(browser.current_url)
browser.save_screenshot("baidu.jpg")
Image("baidu.jpg")
结果:
https://www.baidu.com/
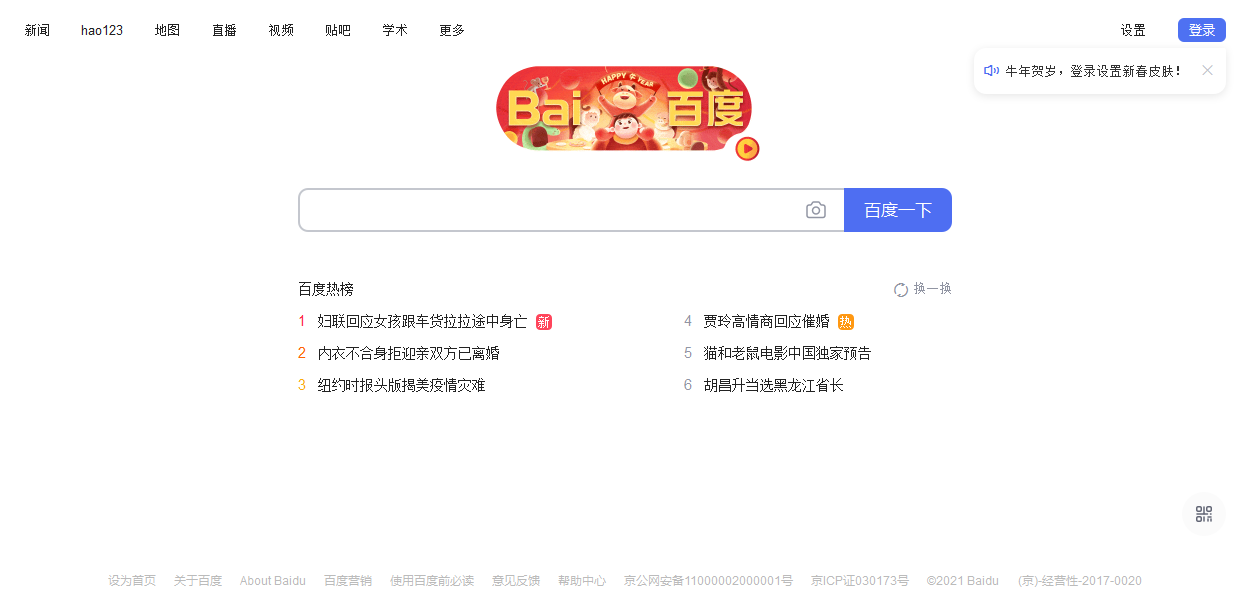
顺利打印出当前URL说明配置正确。
使用远程WebDriver
首先去http://selenium-release.storage.googleapis.com/index.html下载一个Selenium 服务器jar包。
我在http://npm.taobao.org/mirrors/selenium下载了3.9的版本:
http://npm.taobao.org/mirrors/selenium/3.9/selenium-server-standalone-3.9.1.jar
在服务器上通过下列命令运行服务器:
java -jar selenium-server-standalone-3.9.1.jar
注意:需要先安装jdk,将java的bin目录和jre/bin目录加入环境变量
Selenium 服务运行后, 会看到类型这样的提示信息:
D:\develop\phantomjs\bin>java -jar selenium-server-standalone-3.9.1.jar
22:09:10.574 INFO - Selenium build info: version: '3.9.1', revision: '63f7b50'
22:09:10.575 INFO - Launching a standalone Selenium Server on port 4444
2021-02-25 22:09:10.685:INFO::main: Logging initialized @347ms to org.seleniumhq.jetty9.util.log.StdErrLog
2021-02-25 22:09:10.768:INFO:osjs.Server:main: jetty-9.4.7.v20170914, build timestamp: 2017-11-22T05:27:37+08:00, git hash: 82b8fb23f757335bb3329d540ce37a2a2615f0a8
2021-02-25 22:09:10.785:WARN:osjs.SecurityHandler:main: ServletContext@o.s.j.s.ServletContextHandler@16a0ee18{/,null,STARTING} has uncovered http methods for path: /
2021-02-25 22:09:10.788:INFO:osjsh.ContextHandler:main: Started o.s.j.s.ServletContextHandler@16a0ee18{/,null,AVAILABLE}
2021-02-25 22:09:10.986:INFO:osjs.AbstractConnector:main: Started ServerConnector@2150e51a{HTTP/1.1,[http/1.1]}{0.0.0.0:4444}
2021-02-25 22:09:10.986:INFO:osjs.Server:main: Started @648ms
22:09:10.987 INFO - Selenium Server is up and running on port 4444
下面我们可以连接这个远程WebDriver。
测试CHROME:
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444/wd/hub',
desired_capabilities=DesiredCapabilities.CHROME)
测试Firefox:
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444/wd/hub',
desired_capabilities=DesiredCapabilities.FIREFOX)
如果顺利的打开本地的游览器,说明成功使用了远程的驱动。
Selenium的使用
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些 JavaScript 动态渲染的页面来说,此种抓取方式非常有效。
由于新版Chrome 已经支持无头模式可以替换PhantomJS,下面仅以 Chrome 为例:
获取单个节点的方法
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
下面我们希望能访问淘宝页面并进行搜索,首先要观察它的源代码:
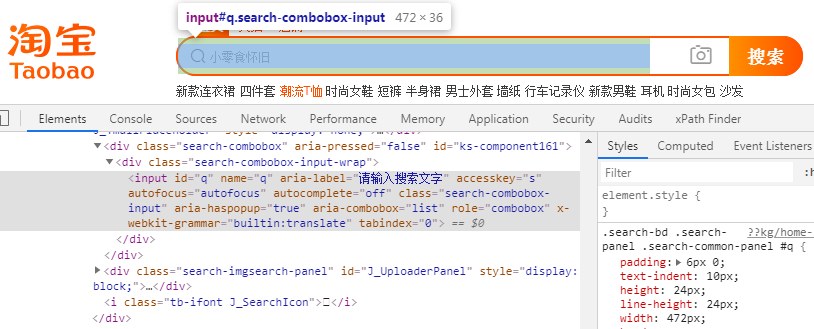
可以发现,它的 id 是 q,name 也是 q。则可以通过find_element_by_name() 和find_element_by_id() 或 XPath、CSS 选择器获取该节点。
代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
a = browser.find_element_by_id('q')
b = browser.find_element_by_name('q')
c = browser.find_element_by_xpath('//*[@id="q"]')
d = browser.find_element_by_css_selector('#q')
print(a, b, c, d)
print(a == b == c == d)
browser.close()
结果:
<selenium.webdriver.remote.webelement.WebElement (session="17c05d43f05c8438bffd99e0af5c1688", element="3483985d-1728-4251-866a-29e9626d7777")> <selenium.webdriver.remote.webelement.WebElement (session="17c05d43f05c8438bffd99e0af5c1688", element="3483985d-1728-4251-866a-29e9626d7777")> <selenium.webdriver.remote.webelement.WebElement (session="17c05d43f05c8438bffd99e0af5c1688", element="3483985d-1728-4251-866a-29e9626d7777")> <selenium.webdriver.remote.webelement.WebElement (session="17c05d43f05c8438bffd99e0af5c1688", element="3483985d-1728-4251-866a-29e9626d7777")>
True
从结果可以看到这四种方式获取到的节点完全一致。
另外,Selenium 还提供了通用方法 find_element(),它需要传入两个参数:查找方式 By 和值。实际上,它就是 find_element_by_id() 这种方法的通用函数版本,比如 find_element_by_id(id) 就等价于 find_element(By.ID, id),二者得到的结果完全一致。上面的代码等价于:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
a = browser.find_element(By.ID, 'q')
b = browser.find_element(By.NAME, 'q')
c = browser.find_element(By.XPATH, '//*[@id="q"]')
d = browser.find_element(By.CSS_SELECTOR, '#q')
print(a, b, c, d)
print(a == b == c == d)
browser.close()
获取多个节点
如果查找的目标在网页中只有一个,那么完全可以用 find_element() 方法。如果有多个节点,只需要用 find_elements() 方法即可,相对原有的方法多个s。
find_elements_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
例如我们想获取淘宝左侧导航条的所有条目:
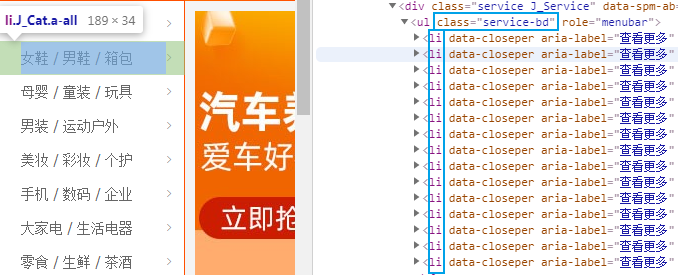
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd li')
for li in lis:
print(li.text)
browser.close()
结果:
女装 / 内衣 / 家居
女鞋 / 男鞋 / 箱包
母婴 / 童装 / 玩具
男装 / 运动户外
美妆 / 彩妆 / 个护
手机 / 数码 / 企业
大家电 / 生活电器
零食 / 生鲜 / 茶酒
厨具 / 收纳 / 清洁
家纺 / 家饰 / 鲜花
图书音像 / 文具
医药保健 / 进口
汽车 / 二手车 / 用品
房产 / 装修家具 / 建材
手表 / 眼镜 / 珠宝饰品
find_element() 方法,只能获取匹配的第一个节点,结果是 WebElement 类型。如果用 find_elements() 方法,则结果是列表类型,列表中的每个节点是 WebElement 类型。
节点交互
Selenium 可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用 send_keys 方法,清空文字时用 clear 方法,点击按钮时用 click 方法。示例如下:
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
kw = browser.find_element_by_id('q')
kw.send_keys('iPhone')
time.sleep(1)
kw.clear()
kw.send_keys('iPad')
button = browser.find_element_by_css_selector('button.btn-search')
button.click()
更多交互操作可参考:
https://selenium-python-zh.readthedocs.io/en/latest/api.html#module-selenium.webdriver.remote.webelement
动作链与切换Frame
在上面的实例的交互动作中都是针对某个节点执行的。比如,输入框的输入文字和清空文字方法,按钮的点击方法。而动作链操作没有特定的执行对象,比如鼠标拖曳、键盘按键等。
下面实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
依次选中要拖曳的节点和拖曳到的目标节点,接着声明 ActionChains 对象调用其 drag_and_drop() 方法申明拖拽动作,最后调用 perform() 方法执行动作:
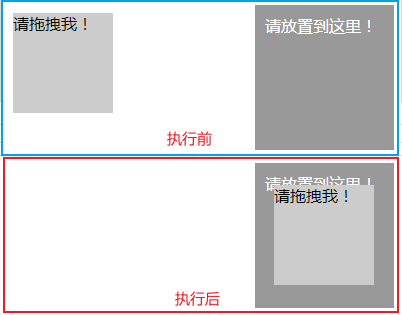
更多的动作链可参考官方文档:https://selenium-python-zh.readthedocs.io/en/latest/api.html#module-selenium.webdriver.common.action_chains
网页中有一种节点叫作 iframe,也就是子 Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium 打开页面后,它默认是在父级 Frame 里面操作,而此时如果页面中还有子 Frame,它是不能获取到子 Frame 里面的节点的。这时就需要使用 switch_to.frame() 方法来切换 Frame。
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
结果:
NO LOGO
<selenium.webdriver.remote.webelement.WebElement (session="8e7770be4454e0e00c28ced1e7d1e514", element="af1acc6a-a662-4cd3-bf7a-cd74c1dfa374")>
RUNOOB.COM
通过 switch_to.frame() 方法切换到子 Frame 里面,然后尝试获取子 Frame 里的 logo 节点(这是不能找到的),如果找不到的话,就会抛出 NoSuchElementException 异常,异常被捕捉之后,就会输出 NO LOGO。接下来,重新切换回父级 Frame,然后再次重新获取节点,发现此时可以成功获取了。
执行 JavaScript
例如我们可以通过执行 JavaScript来滑动窗口,或弹出提示:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
execute_script() 方法即可执行JavaScript。
获取节点信息
通过 page_source 属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery 等)来提取信息了。
但 Selenium 选择节点返回的 WebElement 类型,也有提取节点信息的方法,不需要使用额外的解析库。
获取属性:
get_attribute() 方法获取知乎发现页面第一张图片的地址:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
logo = browser.find_element_by_tag_name('img')
print(logo)
print(logo.get_attribute('src'))
结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="60a9ae1ff2d47ca75849173e7f75992a", element="dcd8597b-888c-4d37-9cf0-a4e6219ed860")>
https://static.zhihu.com/heifetz/assets/loginBackgroundImg.2c81e205.png
获取文本值、ID、位置、标签名、大小:
WebElement 节点的 text 属性可以返回对应节点的文本内容,ID、位置、标签名、大小也有相应的属性可以获取:
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
element = browser.find_element_by_css_selector('footer a')
print(element.text)
print(element.id)
print(element.location)
print(element.tag_name)
print(element.size)
延时等待
有时某些页面有额外的 Ajax 请求,直接获取某些节点可能会有获取失败,这时可以通过延时等待一定时间,确保节点已经加载出来。
等待的方式包括 隐式等待 和 显式等待。
隐式等待:
当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间后再查找 DOM,超过设定时间仍未找到则抛出找不到节点的异常。
用 implicitly_wait() 方法可实现隐式等待:
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
submit = browser.find_element_by_id('su')
print(submit)
显式等待:
显式等待指定了一个最长等待时间,在规定时间内加载出要查找的节点,就返回该节点;如果到了规定时间依然没有加载出该节点,则抛出超时异常。相对固定等待时间的隐式等待一般会节省一些等待时间。显式等待简单来说,就是直到元素出现才去操作,如果超时则报异常。隐式等待是每隔一小段时间就去查找一下需要查找的节点,超时仍未找到则抛异常。
显式等待示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser, 10)
kw = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(kw, button)
presence_of_element_located 条件代表节点出现,其参数是节点的定位元组。element_to_be_clickable条件代表节点可点击。
WebDriverWait 对象指定最长等待时间,调用 until() 方法传入要等待的条件。
常见等待条件有:
| 等待条件 | 含义 |
|---|---|
| title_is | 标题是某内容 |
| title_contains | 标题包含某内容 |
| presence_of_element_located | 节点加载出,传入定位元组,如 (By.ID, ‘p’) |
| visibility_of_element_located | 节点可见,传入定位元组 |
| visibility_of | 可见,传入节点对象 |
| presence_of_all_elements_located | 所有节点加载出 |
| text_to_be_present_in_element | 某个节点文本包含某文字 |
| text_to_be_present_in_element_value | 某个节点值包含某文字 |
| frame_to_be_available_and_switch_to_it frame | 加载并切换 |
| invisibility_of_element_located | 节点不可见 |
| element_to_be_clickable | 节点可点击 |
| staleness_of | 判断一个节点是否仍在 DOM,可判断页面是否已经刷新 |
| element_to_be_selected | 节点可选择,传节点对象 |
| element_located_to_be_selected | 节点可选择,传入定位元组 |
| element_selection_state_to_be | 传入节点对象以及状态,相等返回 True,否则返回 False |
| element_located_selection_state_to_be | 传入定位元组以及状态,相等返回 True,否则返回 False |
| alert_is_present | 是否出现 Alert |
更多详细的等待条件的参数及用法介绍可以参考官方文档:
下拉滚动
有时需要借助滚动条来拖动屏幕,使被操作的元素显示在当前的屏幕上。滚动条是无法直接用定位工具来定位的。Selenium 里面也没有直接的方法去控制滚动条,这时候只能借助 JS 来完成了,可以用 selenium 提供的 execute_script() 方法操作,就可以直接执行 JS 脚本。
通过修改 scrollTop 的值,来定位右侧滚动条的位置,0是最上面,100000是最底部。
browser.execute_script("document.documentElement.scrollTop=100000")
还可以通过左边控制横向和纵向滚动条 scrollTo(x, y) 操作页面。
browser.execute_script("window.scrollBy(0,100000)")
让页面跳到指定元素的位置:
target = browser.find_element_by_id("id")
browser.execute_script("arguments[0].scrollIntoView();", target)
通过定位元素附近选择器或标签等定位元素:
browser.find_element_by_xpath("//div[contains(@id,'id')]/div").click()
通过目标元素的location_once_scrolled_into_view属性:
browser.find_element_by_css_selector('#J_bottomPage > span.p-skip > em').location_once_scrolled_into_view
通过动作链操作移动到指定元素位置:
from selenium.webdriver.common.action_chains import ActionChains
actions = ActionChains(browser)
target = browser.find_element_by_css_selector(
'#J_bottomPage > span.p-skip > em')
actions.move_to_element(target)
actions.perform()
模拟向页面发送空格键实现移动到页面底部:
from selenium.webdriver.common.keys import Keys
browser.find_element_by_tag_name('body').send_keys(Keys.END)
前进后退
平常使用浏览器时都有前进和后退功能,Selenium 也可以完成这个操作,它使用 back() 方法后退,使用 forward() 方法前进。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
Cookies
获取、添加、删除 Cookies ,示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie(
{'name': 'name', 'domain': 'www.zhihu.com', 'value': 'germey'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())
选项卡管理
在 Selenium 中,对选项卡操作,示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
browser.execute_script('window.open()')
browser.switch_to.window(browser.window_handles[2])
browser.get('https://www.runoob.com/')
browser.switch_to.window(browser.window_handles[0])
print(browser.window_handles)
结果:
['CDwindow-C980F58B9B582821A0212671B565C5A2', 'CDwindow-13FAB162A75160561494F8B57E3849B1', 'CDwindow-75ADDB2118C4314E28F990403CB67D5E']
异常处理
在使用 Selenium 的过程中,难免会遇到一些异常,例如超时、节点未找到等错误,一旦出现此类错误,程序便不会继续运行了。这里我们可以使用 try except 语句来捕获各种异常。
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element_by_id('hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()
关于更多的异常类,可以参考官方文档:https://selenium-python-zh.readthedocs.io/en/latest/api.html#module-selenium.common.exceptions
无头模式
Chrome 浏览器从 60 版本已经支持了无头模式,无头模式在运行的时候不会再弹出浏览器窗口,它减少了一些资源的加载,也在一定程度上节省了资源加载时间。
我们可以借助于 ChromeOptions 来开启 Chrome Headless 模式,代码实现如下:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_argument('--headless')
browser = webdriver.Chrome(options=option)
browser.set_window_size(960, 540)
browser.get('https://www.baidu.com')
browser.save_screenshot('baidu.png')
browser.close()
通过 ChromeOptions 的 add_argument 方法添加了一个参数 --headless即可开启无头模式, Chrome 窗口就不会再弹出来了。
反屏蔽
使用正常的浏览器和Selenium启动一个 Chrome 的有头模式打开如下网址:https://bot.sannysoft.com/。可以看到:
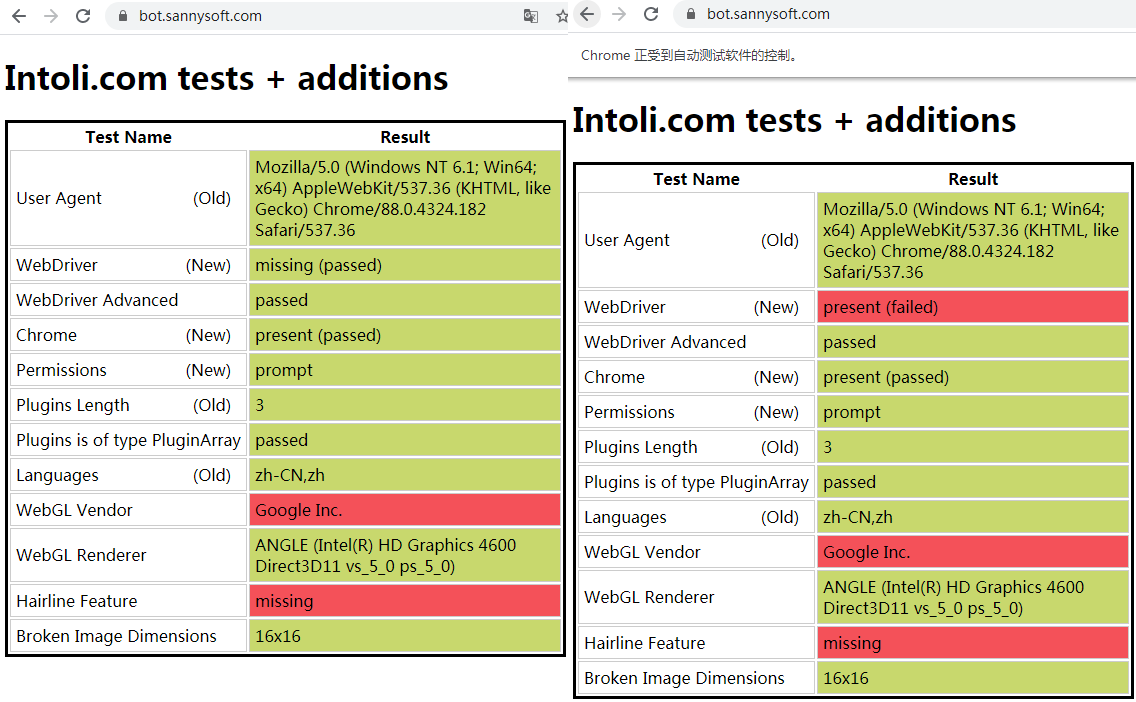
显然Selenium暴露了一些特征,我们需要想办法清除这些信息。
清空webdriver信息的JavaScript代码是:
Object.defineProperty(navigator, "webdriver", {get: () => undefined})
不过我需要通过CDP(即 Chrome Devtools-Protocol,Chrome 开发工具协议)实现在每个页面刚加载的时候执行 JavaScript 代码,隐藏一些特征信息。
88版本完整解决方案:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
option.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
option.add_argument("--disable-blink-features=AutomationControlled")
browser = webdriver.Chrome(options=option)
with open('stealth.min.js') as f:
js = f.read()
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': js
})
browser.get('https://bot.sannysoft.com/')
实验性功能参数 excludeSwitches的值设为 ['enable-automation']可以关闭Chrome 正在受自动化测试工具控制的提示条,useAutomationExtension设为False则关闭了以开发者模式运行扩展程序。
设置两个普通参数使后续代码能够生效。使用 CDP执行的JavaScript代码是专门用来隐藏 Selenium 或 Pyppeteer的特征的,由puppeteer-extra-plugin-stealth的作者写的extract-stealth-evasions工具生成。
具体生成方法可参考:
puppeteer-extra-plugin-stealth: https://github.com/berstend/puppeteer-extra/tree/master/packages/puppeteer-extra-plugin-stealth
extract-stealth-evasions: https://github.com/berstend/puppeteer-extra/tree/master/packages/extract-stealth-evasions
可直接从https://github.com/kingname/stealth.min.js下载某位大佬已经生成好的。
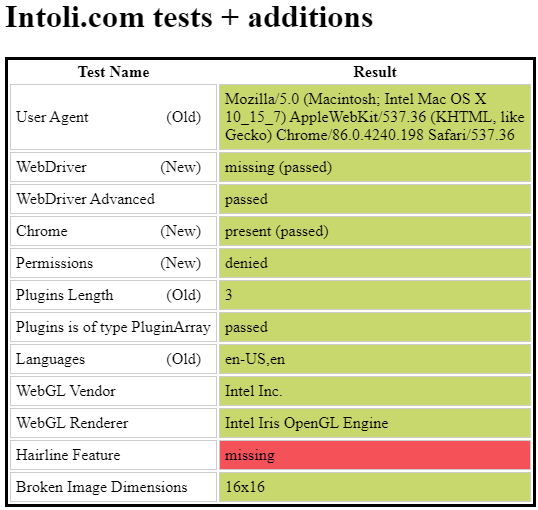
即使处在无头模式下,也可以隐藏WebDriver信息:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_argument("--headless")
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
option.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
option.add_argument("--disable-blink-features=AutomationControlled")
browser = webdriver.Chrome(options=option)
with open('stealth.min.js') as f:
js = f.read()
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': js
})
browser.get('https://bot.sannysoft.com/')
browser.save_screenshot('walkaround.png')


评论